
�ֲ�ʽ�������Ĺ��c�ࣿ���й����Ό��F�����\�S

�S���Ñ��������Ĺ��c�����࣬�ڹ��픵�������ϣ��W�jͻȻ�Дࡢ�����߁K�l���W�j���î������W��Ӳ�������Ȇ��}�r�аl���������˹��ք��M�оW�j�|�������Ϸ������K��������M�й���̎�õĂ��y�\�S��ʽ���o��ȫ�渲�w�������ij��F�Ć��}��
���ˣ��ŷ���й���аl���W�jȫ�·�|����֪�c����ϵ�y��
ԓϵ�y�܉�C���\�I�̡������W�j�����C�W�j��VPC�W�j�ȶ��ӾW�jҕ�ǣ�Ϊ��άʹ�����ṩһ��ȫ��·����������֪�����ܷ�����Q���� ����Ч�����澯�|���澯������Ч����
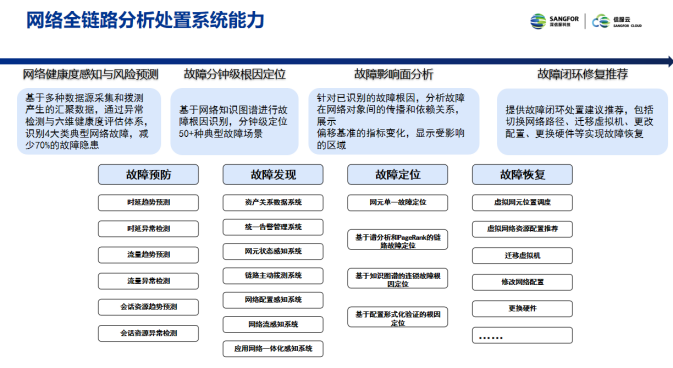
�W�jȫ�·����̎��ϵ�y����
�W�j�·���ӓܜy
���ԃ����O�y��������ҕ�Y�����K���������[�P�澯�Ԅ��ھ�;ۺϷ����ۺϿs�p�DZ�Ҫ�ıO�y�澯�����R���l�F�W�jͨ�༰�������ڴ����澯�п��ٶ�λ������IaaS����T��������C��������ľW�j�Bͨ�Ԡ�B�����������������̓�M�C�Ȳ��ľW�j��B��档
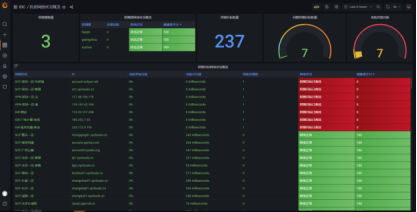
�ṩȫ��̽�y�������Y����Ԕ��
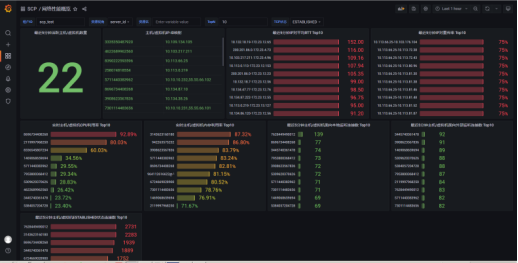
�ṩ̓�M�C�Ȳ��˵���TCP/UDPͨ�Ō��ľW�j�|����ҕ�c����
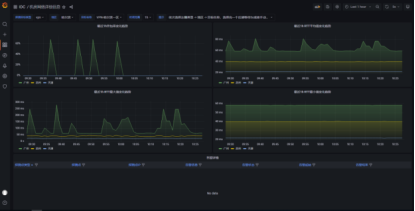
����RTT�r�ӄӑB�������L�U�A�y
����RTT�r�ӄӑB�����M���L�U�A�y��֧�����ܻ������ԄӌW����ͨ�^��������B��ָ�˵ĕ�ʷ���F�������{���������������c����ͬ�ӕr�εČ��rָ�������ȣ��ܸ�����ʷӛ��Ԅ����ɻ������K�ɰ��I�����ڳ�ϫ׃��Ҏ�ɣ��γ����ջ������ܻ����Ĕ������ȣ�һ�����r�������ڻ����Ȍ���һ�������������ɸ澯�¼����ɹ��A�y�L�U��
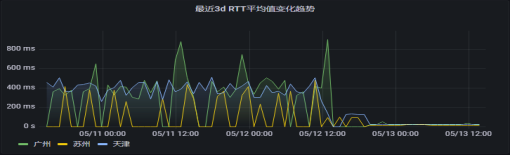
׃��څ���A�y
ͬ�r��ԓϵ�y߀�������M����δ�����Ԍ��F̓�M�C�Ȳ��đ��þW�j�|����ƽ̨IaaS�ӵ�һ�w���Ӷ�ģ�B���������F����Ĺ��϶��硣
����ȫ��ָ�˘������w�YԴ�D�V�wϵ��IT�\�S�ˆT�����ϕr��Ҳ��ͨ�^�P������5���R�ȶ�λ��̓�M�C�Ȳ����ⲿ���ϸ����̎�ý��h����������֪�R�D�Vֱ�^����ƽ̨������B����Ӱ����С��
�ھW�j�YԴ�������]�ϣ�����ȫ��O��̓�M�W�j�ؓ䡢���á��������������B�Ȕ��������ö�N�C���W���������F�_�Ĕ��������܉�����Ӌ�����ڔ��������܉������W�j������ʷڅ�ݣ��P�A�y���������ܘO���F�r�g�c�K���]��������YԴ���á�
���Ͼ��ǹ����ŷ����й����ϾW�jȫ�·�|����֪�c����ϵ�y�Ľ��ܣ���ϵͳ�������û�������������ʣ�ʵ���������ĵ�ʡ����ά��